Distributed Orchestration
Preamble
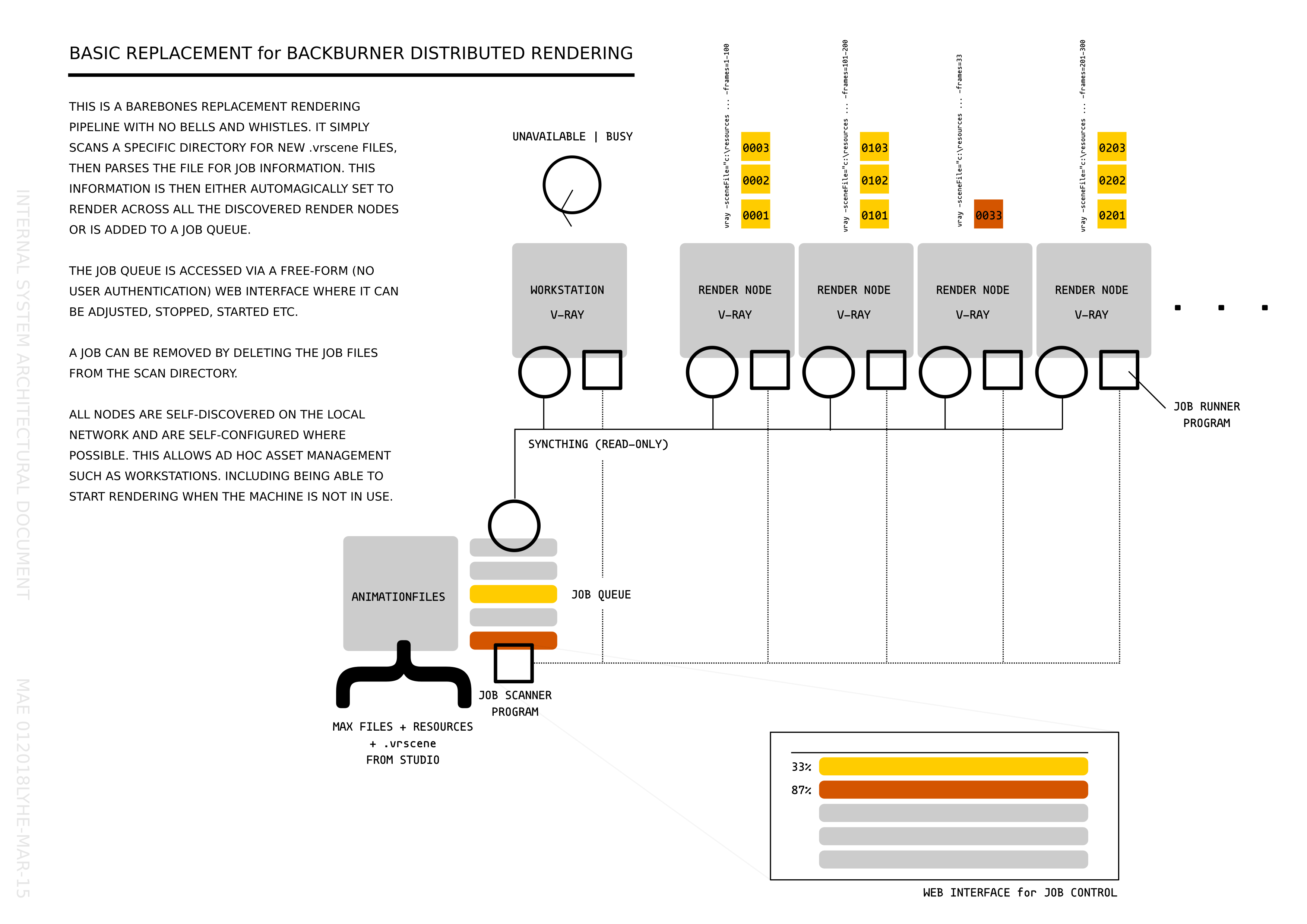
This case study is about replacing an existing rendering pipeline orchestration system (backburner software provided with 3-d Studio MAX) with a more flexible custom one geared around the premise of ad hoc distribution on local resources.
This is the first toy implementation of an ad hoc network of computing resources working to fulfill tasks generated by users or other tasks. The main aim of this toy is to avoid as much configuration as possible. We attempt to do this by designing a system with as few central points as possible.
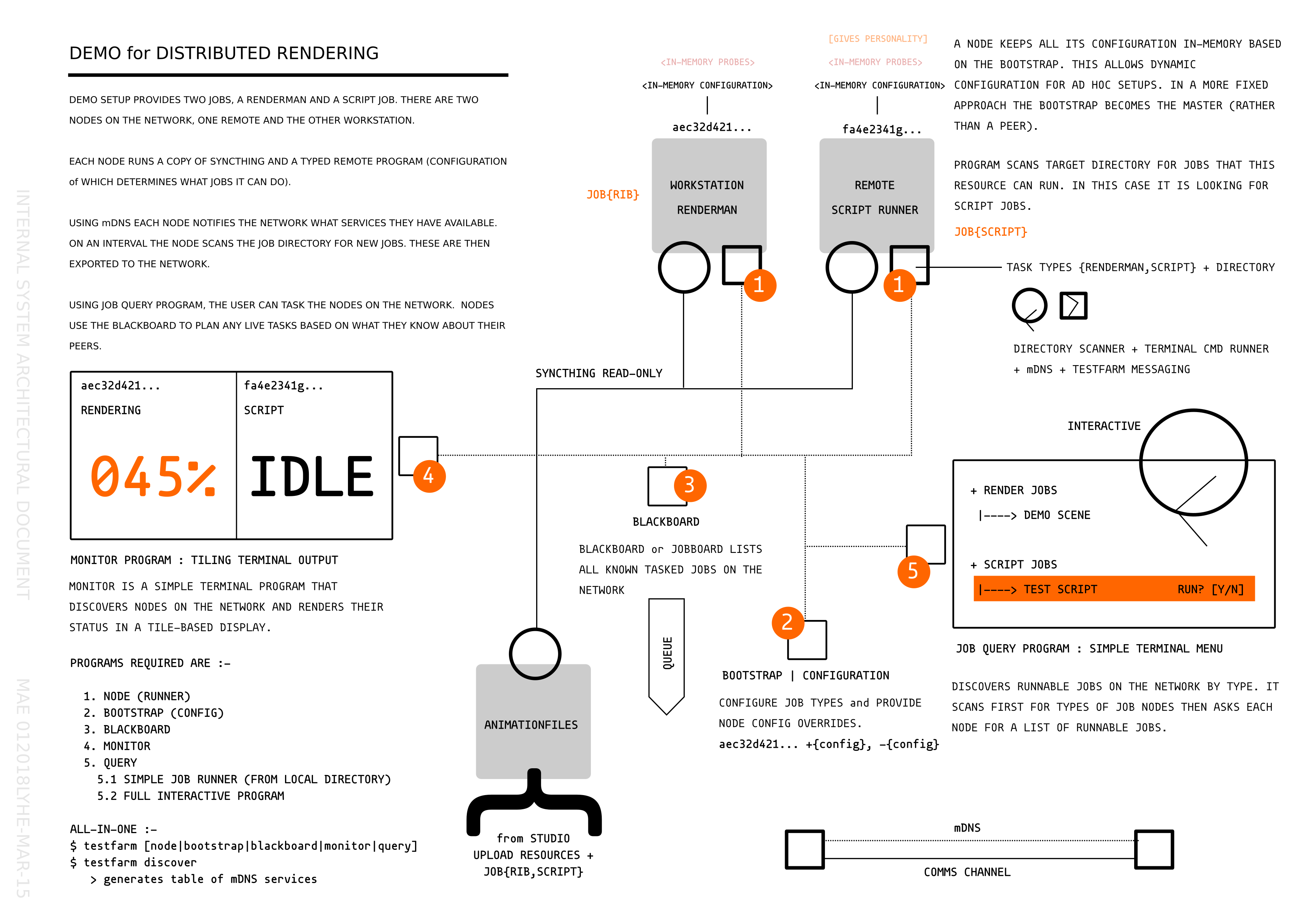
Services are local network discoverable and configurable. In this toy we have a program called worknode. This program periodically scanes a jobs directory (in this case an export folder from the syncthing service) looking for potential job files. What it looks for, in this case, is renderman jobs [files ending with .rib] and python scripts [files engine with .py].
In my local test network I have a single vm computer named Sally with python installed; on my workstation Marvin I have Pixar’s Photorealistic Renderman (prman) software installed. Each program works out what is installed and then applies that knowledge to what jobs are available, reading from the same export directory from syncthing (in both cases).
As a user on this network I can gather the exported information about potential jobs available to me to run on the network. I can then ask for a job to be processed by issuing a single command. The network then determines whom does what and how.
Video
In this video I demo the current testfarm program, currently only implemented as a command line program; firstly I look at the network for what resources are available to me; I then run the program in worknode mode, creating a new resource on the network from my workstation; looking at the network again we see that we have two resources: Sally has found one python job, whilst Marvin has found three prman jobs; I then query for what those jobs are, then I choose to run a prman job. Because prman is running directly on my workstation (Marvin) it starts the render job on my desktop writing the resulting output to a frame buffer onscreen.
Program Notes
The program makes use of mDNS service to stitch togeather the local available resources, the rest is implemented on standard file-system APIs. At this point the only exported information from each hosted program is the computing resources available.
Future
The current program uses a custom network protocol to talk with each other, this will be replaced with the HTTP (web) protocol, as this will allow users to directly inspect individual resources via a webbrowser.
A future version may introduce a blackboard mode, where a resource will run as a network wide storage of information for users and other resources to mark their actions and planning. This allows rendernodes, for instance, to planout their work so that their peers are not simply rendering the same frames. Because we give the rendernode control over work (and style of work) we can do things like automagically comparing rendering speeds amongst peers – coming to an arrangement over the amount of work each does.
As a goal is to replace backburner ontop of the orchestration program (above) we will look at adding a more expected renderfarm tool, this will be a web based service that will talk to all network resources on behalf of the users. This effectively re-centralises everything for the rendering pipeline.